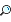

HELLODBA.COM> select sid, event, p1, p2 from v$session_wait_history where sid in (select sid from v$mystat) and event = 'enq: TX - index contention'; SID EVENT P1 P2 ---------- -------------------------------- ---------- ------ 307 enq: TX - index contention 1415053316 589842 |
如果条件允许,将10046 Trace打开(level 8以上),从SQL_TRACE文件中,可以得到该等待的相关信息:
WAIT #3: nam='enq: TX - index contention' ela= 786 name|mode=1415053316 usn<<16 | slot=589842 sequence=143247 obj#=198789 tim=2042412966 |
要注意的是,这一请求模式也是共享模式,obj#信息也并不准确,如在上面的trace文件中,部分该等待显示的obj#是198656――它是表tx_index_contention,而非索引。但是,因为该等待事件只会发生在索引上面,这一点可以帮助我们判断等待对象是否正确。
由于"index contention"是发生在索引分裂时,索引分裂是由递归事务所控制,单次等待出现的时间很短暂,因此对于该等待的监控分析重点于监控系统中发生导致该等待最多的索引对象:
HELLODBA.COM>select * 2 from (select o.owner, o.object_name, count(1) cnt 3 from dba_hist_active_sess_history s, dba_objects o 4 where s.event = 'enq: TX - index contention' 5 and s.current_obj# = o.object_id(+) 6 and o.object_type = 'INDEX' 7 group by (o.owner, o.object_name) 8 order by count(1) desc) 9 where rownum <= 10; |
要注意的是:当大量数据被删除后,某些数据块上没有数据了,被放入了freelist(无论事务是否已提交)前列,但是并没有从B+Tree结构中拿掉。当有节点发生分裂时,会先从freelist上找空闲数据块,但此时该数据块并不能作为新数据块用于分裂(因为删除数据事务未提交;或者因为符合索引顺序的数据被写入该数据块),节点分裂的事务就会发现该数据块不可用,于是放弃它、继续找下一空闲数据块,如此类推,分裂事务发生“db file sequential read”等待,而被分裂的数据块则被其加载了共享锁,而如果此时有其他事务需要想该数据块写入数据,则会被放到等待队列中去,并记录"enq: TX - index contention"事件。
解决方法
从前面的分析得知,引起该等待的原因是索引分裂,要降低等待次数,需要减少索引分裂的发生。而要减少索引分裂的发生,可以视应用情况,采用下面的手段:
减小索引大小。以下是一些减小索引大小的可选方法:
从索引中移除不必要的字段;
调整索引中字段顺序,使选择性更强的字段在前,减小枝节点的大小;
适当使用函数索引,减小索引大小。例如,substr(),ora_hash(),to_date();
创建压缩索引
对于更新很少的表,可以考虑使用大数据块的表空间;
对碎片较多的索引进行Shrink Space或rebuild index,释放空闲数据块;

